
Adding Content
Questions and answers
Q1How does Magnity get content into the platform?
Magnity uses a combination of automatic crawling and manual additions to bring content into the library.
Q2How does the automatic crawler work?
The crawler runs every 6 hours
It is configured via backend rules per market
Crawling is controlled by folder rulesets where paths can be included or excluded.
Example: Include /products/, Exclude /products/producta/.
Each crawl also checks the sitemap for:
- Lastmod values → if a page is updated, it is re-crawled.
- New pages → newly published pages are added.
- Language variants → new /xx/ folders or .xx domains mapped and added.
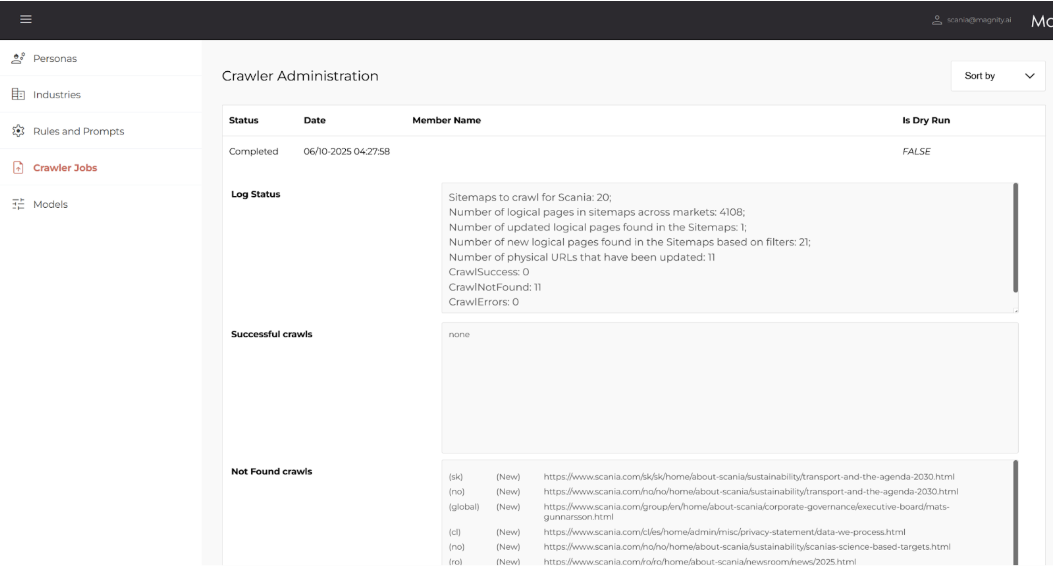
Crawl jobs and results are visible in the Content Engine → Crawler, where you can see:
- Pages identified and crawled
- Success, errors, not found
- Whether content is new or updated
- Which market it belongs to
Q3Why use the crawler?
It ensures content is onboarded automatically, fast, and structured, so teams always work with the latest sources.
Q4How are automatic crawl rules controlled?
Automatic crawl rules are managed in the backend by Magnity Support to avoid extreme jobs (e.g., millions of pages).
You can request adjustments if you want us to: Contact your admin (or us, if you are an admin). Based on the rules we can:
- Include/exclude specific folders
- Add a new folder for automatic crawling
- Look for page variants in a specific subdomain
- Adjust for folder names that differ across markets
- Decide what types of images should be fetched with content
Contact your admin or Magnity Support if you need changes to the crawl configuration.
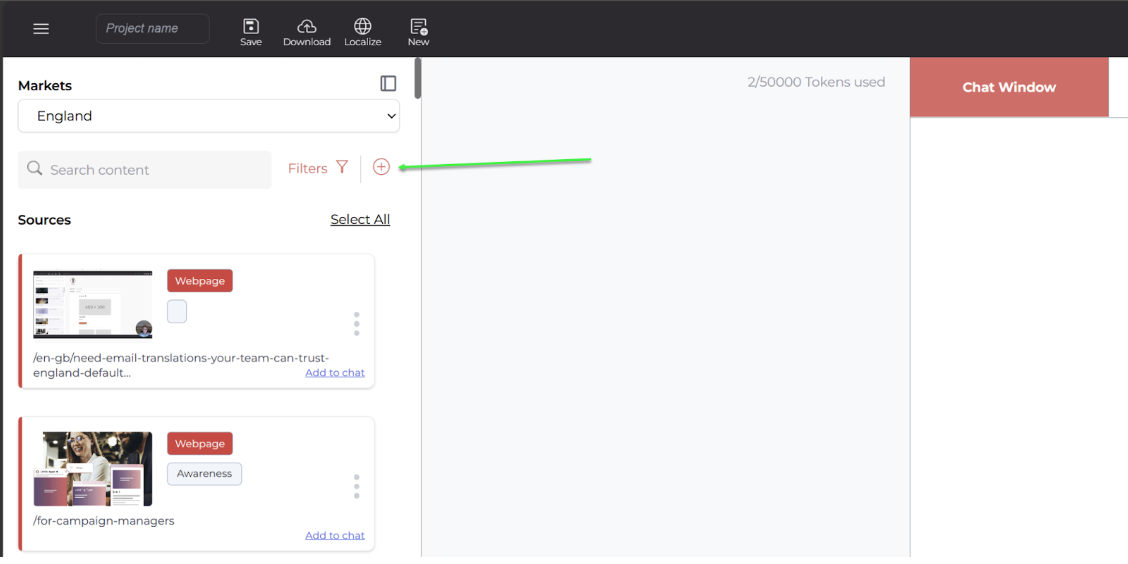
Q5How can I add content manually?
In the content library, click the (+) button next to filters. You have several options:
- Basic email module – Add an already written email manually. Enter elements such as image, headline, body text, etc. Useful for translating or modifying existing emails.
- Raw source – Create a tile by copy-pasting text. This defaults to a webpage-type tile.
- Crawl a URL – Enter a URL to start a crawl job:
- Magnity fetches the page and (if selected) maps language variants.
- For multi-language URLs, the job can take a few minutes.
- Only one manual crawl can run at a time → others are queued.
- Upload document – Upload a PDF to crawl and add into the library. (Currently no automatic mapping of localized PDFs.)
Q6Which manual method supports automatic language mapping?
Only Crawl a URL supports automatic detection and mapping of language variants.
Q7Why is my Save button greyed out when I want to submit any crawl?
There is a good chance you did not add a tag yet. Do so and the button should go orange. Scroll down a bit if you don’t see it.
Q8Where can I see crawl jobs?
In the Content Engine → Crawler, you can see:
- Jobs queued or running
- Success/fail status
- Whether content is new, updated, or unchanged
- Market and language information